


コラム
大規模言語モデルに独自データを追加して問い合わせてみた

DX・新事業推進統括部の池田かずひこです。
会社のアイコン用に作った画像貼り付けてみました・・こんなオヤジが書いています。
ちょんまげではなくソフトモヒカンです。
先日、6月27日~28日に行われたMicrosoft Build Japanに現地参戦してきました。
久々の日本マイクロソフト(品川)本社での開催です。
直接、マイクロソフトの技術者の方や、MVP(Most Valuable Professional)の方々とお話もできて、とても勉強になりました。やはり、オフラインイベントはいいですねぇ。
このイベントのなかで、いろいろな新機能の説明があったのですが、大部分がAIに関連したものでした。マイクロソフトのAIに対する本気度を感じました。
インターネット・SNS上でも、「ChatGPTを使ってみた・・」や「社内でChatGPT使うには?」のような話題があふれかえっています。
前回、『次回のブログでは、上記のように社内の情報も考慮した回答を可能としてくれるエンベディング(Embedding)等の手法を「追加してみた!」をお伝えできればと思います。』と書いてしまってちょっと後悔しています。難しかったです。
Embeddingって?
単語や文章を数値データ化(ベクトル化)することをEmbeddingと言います。Azure OpenAI Serviceにも、この処理に利用できるEmbedding用のモデルが提供されています。
Azure OpenAI Serviceで現在提供されているEmbedding用のモデルは3種類あります。
- Similarity :複数のテキスト間の意味的な類似性を捉えるのに便利
- Text Search :短いお問い合わせ文章に対して、回答の文章がどのくらい関連しているかを測定するのに便利
- Code Search :コードスニペットを埋め込んだり、自然言語のクエリを埋め込むのに便利
このように、Embeddingは文章同士の類似度を計算できたり検索等にも利用可能なので、複数の学習モデルを利用したシステムでの、モデル選定前処理にも用いられます。
今回は、外部には公開できない情報(たとえば社内の規則、規程など)に関するお問い合わせに回答できる動作を実現したいと思うので、Text Searchを利用しました。
ちなみに自然言語を生成するためのテキストベースモデルはCompletion用のモデルになります。
架空の会社 “そふとはうす池田屋” の就業規則 お問い合わせ
同僚から、「会社の就業規則って難しいからChatGPTにわかりやすく回答してもらえるようなものが欲しいね♪」とアイデアをもらっていたので、架空の会社 “そふとはうす池田屋” の就業規則を捏造して、さっそく作ってみることにしました。
- ※ベースは厚生労働省のHPで公開されている「モデル就業規則」です。
- 厚生労働省ホームページ「モデル就業規則」(外部サイトへ)
一日5時間勤務や週休3日制、ジャパンラグビー リーグワン開催期間は休日、給与はペソでの支払い等、やりたい放題の就業規則に仕立てました!
作業の流れ
実現するための作業の流れは、下記のとおりです。
- 利用したい社内情報の選定
- 選定情報ファイルの下ごしらえ
- ファイルの分割
- 分割したファイルのベクトル化
- お問い合わせ文章のベクトル化
- お問い合わせに対応するファイルの取得
- お問い合わせ文章と取得ファイル内容を結合
- GPTに対してのお問い合わせ
利用したい社内情報の選定
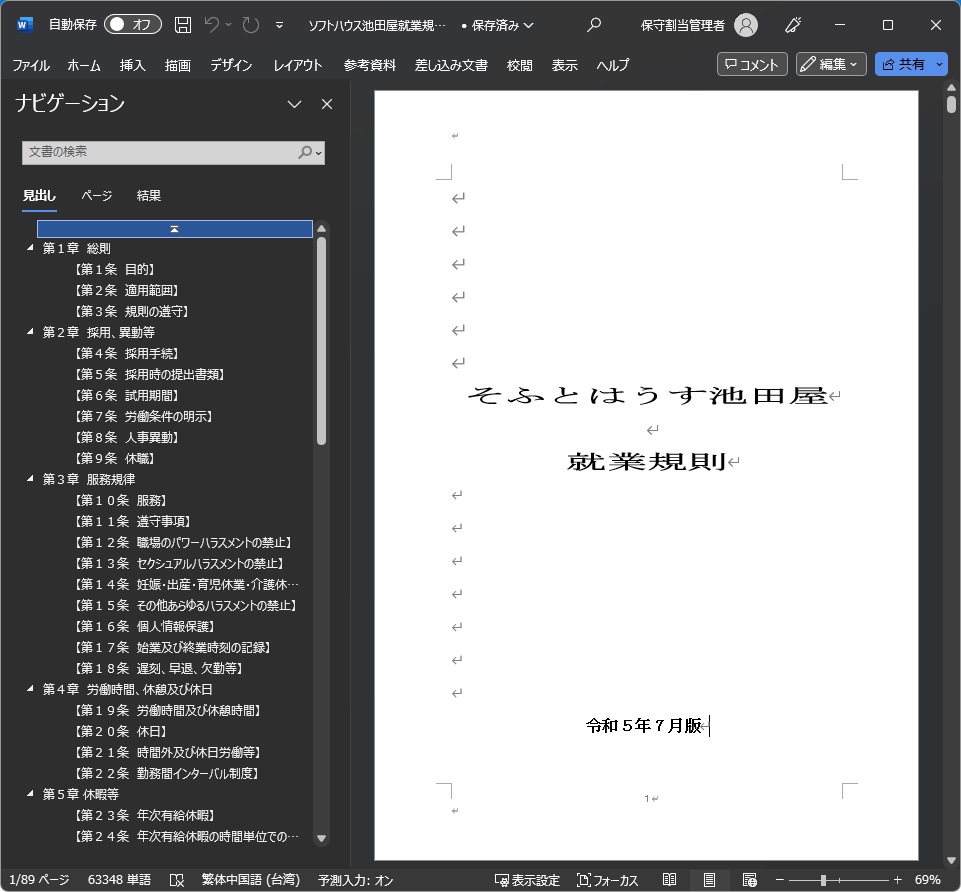
今回は、「そふとはうす池田屋就業規則.doc」の1ファイルを対象として選定しました。実際は、就業規則細則等の関連情報も含めた複数ファイルも選定可能です。
【私見的なノウハウ】
信頼できる文章を選択しましょう!
⇒あいまいな文章はあいまいな回答しか返ってきません。
選定情報ファイルの下ごしらえ
通常、社内情報ファイルはPDFやOfficeドキュメント内で、文章や図、表を使って記述されています。
Embeddingは文章を対象としているので、図や表での表現も文章で説明してあげる必要がありました。
今回利用した手法とは異なりますが、Azure Cognitive Searchには、文章(テキスト)以外に図なども内部的にベクトル化を行う、「インデックス検索」や「セマンティクス検索(意味的に近いモノの検索)」の機能が備わっています。
【私見的なノウハウ】
下ごしらえには気力と体力が必要です!
⇒PDFをテキストに変換する方法は多数存在して単純変換はできたのですが、文章がページにまたがっていたり、ヘッダやフッタの文字列が作業の邪魔をします。エディタ(僕はジジィなのでVim派)を駆使して格闘しました。
ファイルの分割
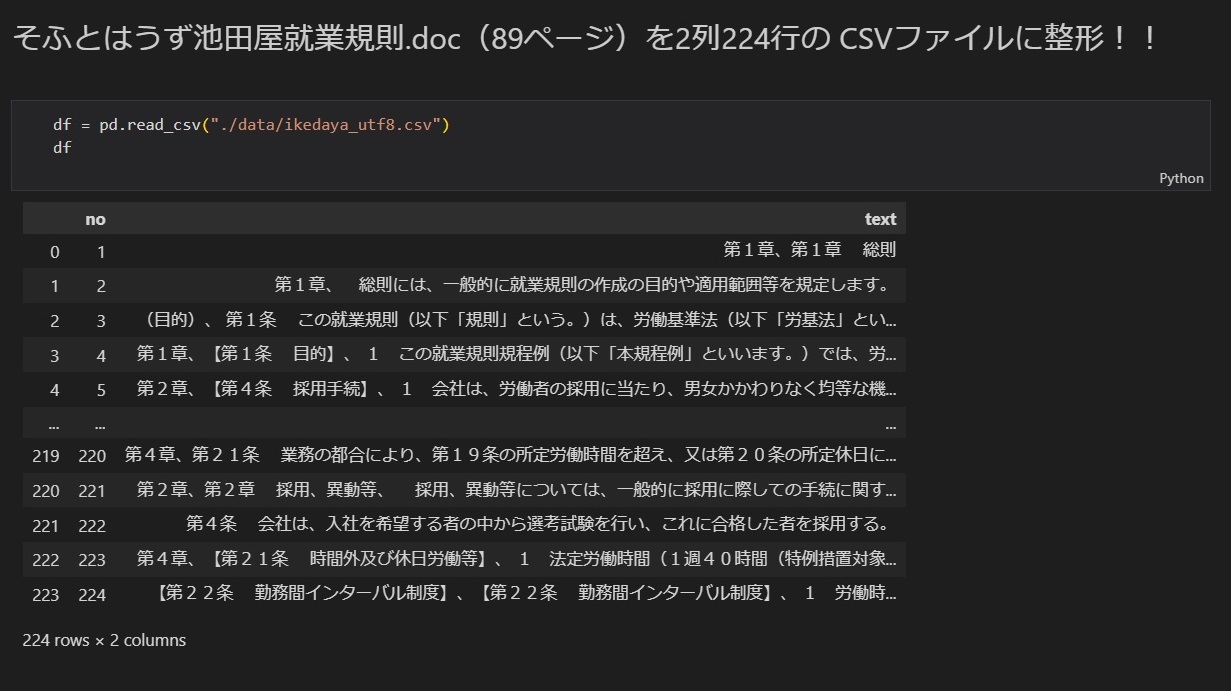
Azure OpenAI Serviceが提供しているモデルには、一度に処理できるトークン数に上限があります。(作業を行っていた時点での上限は、gpt-35-turboでは4,096トークン、Embedding用モデルでは2,046トークンでした。7月上旬にはさらに拡張されたモデルがリリースされました。)
Embeddingする文章も、上限を超えないサイズにする必要があります。
今回は、就業規則を対象としていたので、「第××条」の単位で分割し、EXCELの力も借りながら1行に1条項のCSVファイルにしてEmbeddingしました。
他にもEmbeddingする対象をそれぞれの小さなファイルとするやり方があります。
日本語のトークン
トークン数は単語の数に一致しないので分かりにくいです。
自然言語処理では形態素解析を行いますが、解析結果の形態素数もトークン数と一致しません。つまりトークン数は、形態素数でも文字数でもバイト数でもない数え方となります。
地道に、Python言語でサイズを確認する処理で確認しながらファイルの大きさを調整しました。
たとえば、「私はホッピーが好きです」という日本語文章のトークン数をOpenAI Tokenizerで確認すると、日本語で11文字に対して、トークン数は「16」と返ってきます。しかし、この文章を形態素解析すると、形態素数は「6」になります。
| 形態素に分割 | 品詞 |
|---|---|
| 私 | 代名詞 |
| は | 助詞-係助詞 |
| ホッピー | 名詞-固有名詞-一般 |
| が | 助詞-格助詞 |
| 好き | 形状詞-一般 |
| です | 助動詞 |
分割したファイルのベクトル化
分割した各テキストファイル(今回はCSVファイル)をAzure OpenAI Serviceでベクトル化(Embedding)します。ここまでの下ごしらえは大変でしたが、ベクトル化(Embedding)は、たった1行でできます!
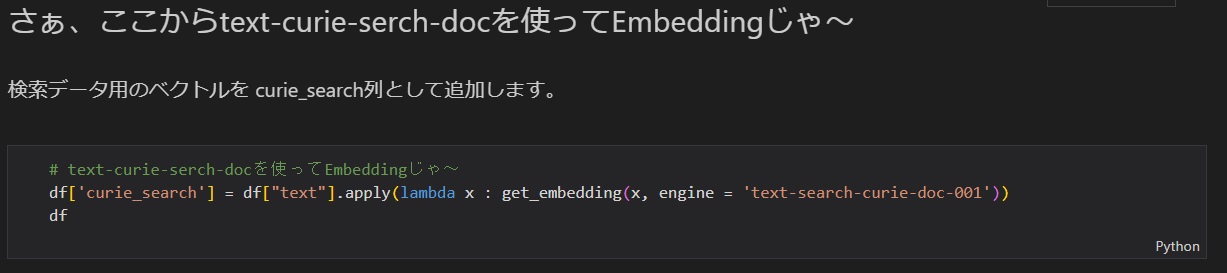
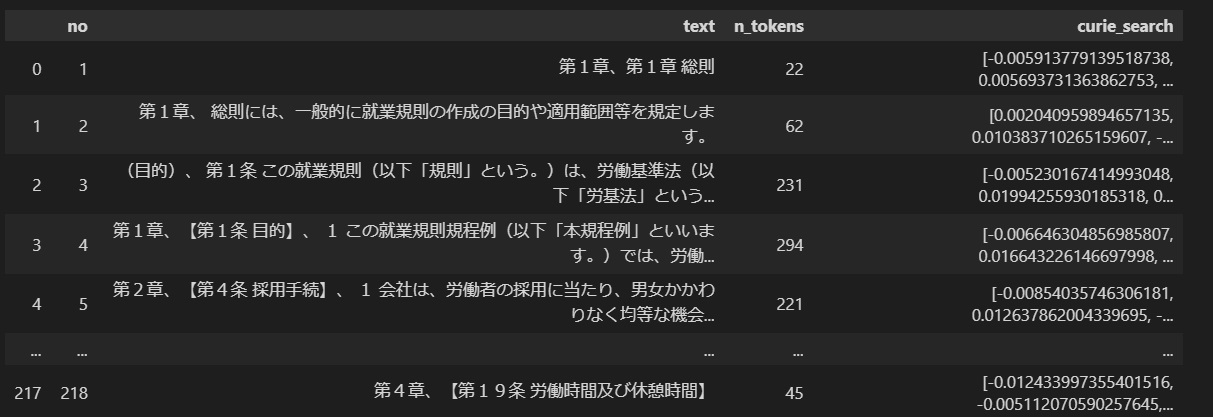
この処理を実行することで、各行に対して検索用のベクトルが追加されます。
元のCSVには、no列、text列があり、n_tokens列にはトークン数、curie_search列にはベクトル化した値が追加されます。
お問い合わせ文章のベクトル化
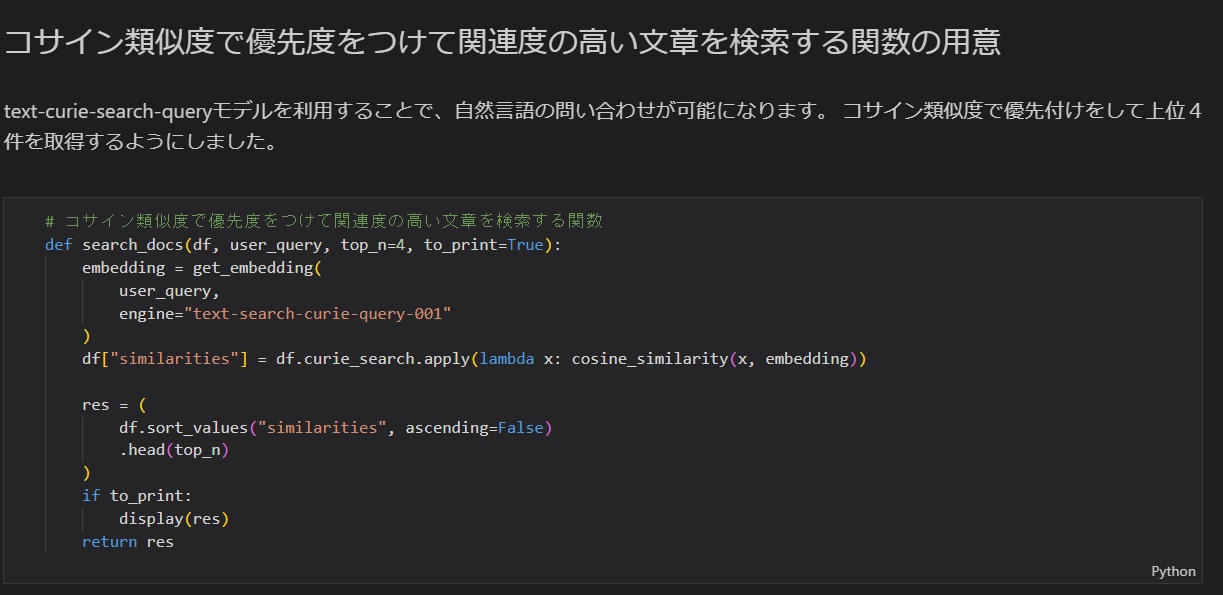
次にお問い合わせの文章をベクトル化し、先ほど追加した検索対象側のベクトル化した値との比較により、関連性のある情報を優先度をつけて抽出する処理を作っておきます。(コサイン類似度比較)
検索結果は関連性の高い上位4つを返却するようにしました。
お問い合わせに対応するファイルの取得
「育児休暇制度はありますか?孫にも適用できますか?」とお問い合わせをしてみます。
(孫1号、孫2号がいる身としては気になる制度です!)
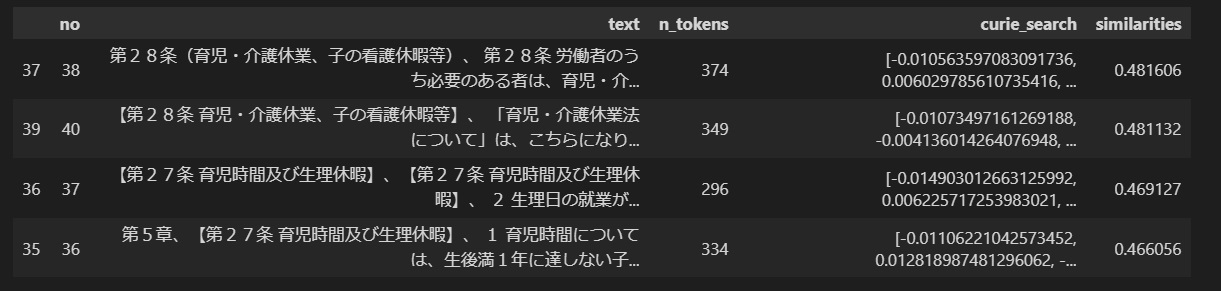
この段階で返却されるのは、お問い合わせ文章のベクトル値と類似した上位4件の情報のみです。下図のようにそふとはうす池田屋の就業規則から4つの条項が返却されて終わりです。
このままでは温かみの無い回答で終わってしまいます。ChatGPTが回答するような自然な文章で回答してほしいですね。
お問い合わせ文章と取得ファイル内容を結合
返却された4つの条項を1つのテキストとして単純結合してみましょう。
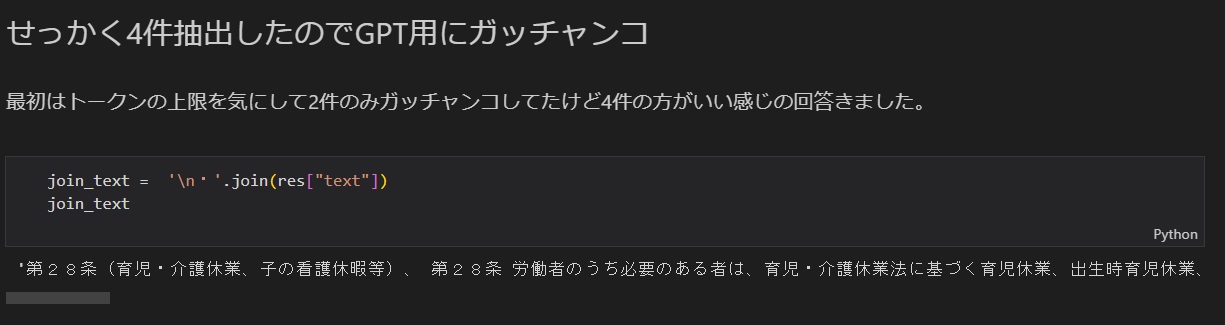
【私見的なノウハウ】
1つに結合した状態でトークン数が上限をオーバしないように元ファイルを下ごしらえするのがミソ
⇒対象とする情報によっては、結合する返却データは類似性の高い上位2件でも良いかもしれません
GPTに対してのお問い合わせ
Azure OpenAI Serviceが提供するGPTモデルには、今まで利用してきたEmbeddingで利用する種類のものと、文章を生成するCompletionの種類があります。CompletionはChatGPTでも利用されています!
Completionにお問い合わせを行う際に、役割や前提条件をプロンプトとして指定することができます。
回答者の立場となるシステムの役割(role: systemの部分)には、
・"あなたは質問に回答する、そふとはうす池田屋の総務担当です。"
を指定しました。
お問い合わせを行うユーザーの役割(role: userの部分)での問い合せ文章は、次の3つのテキストを結合したものを指定しました。
・“育児休暇制度はありますか?孫にも適用できますか?”(元のお問い合わせ)
・“コサイン類似度での比較では次の回答候補を検出しました。この回答を参考にいい感じに回答生成してください。”
・ベクトル同士でのコサイン類似度で比較した上位4件を結合したテキスト(変数:join_text)
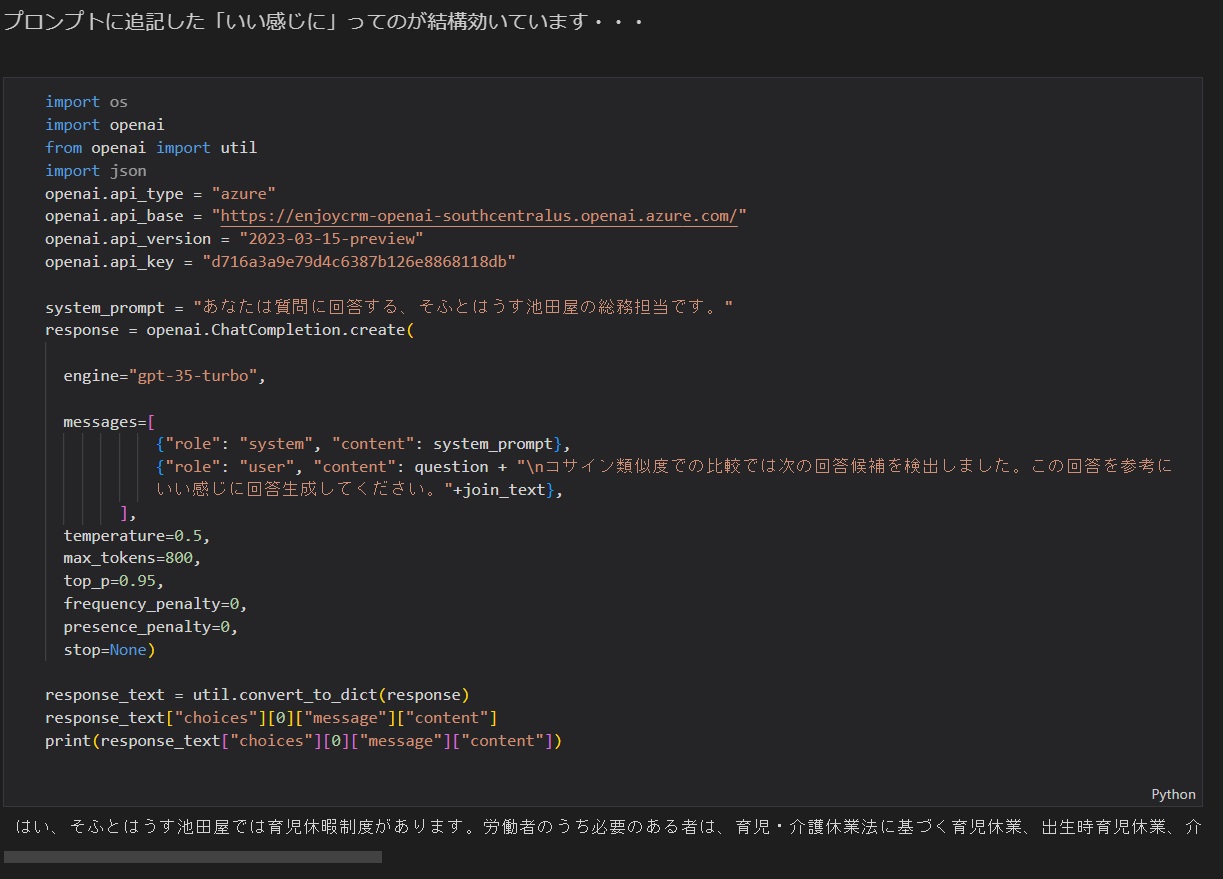
いい感じの回答が返ってきました!
- 【質問】育児休暇制度はありますか?孫にも適用できますか?
- 【回答】はい、そふとはうす池田屋では育児休暇制度があります。労働者のうち必要のある者は、育児・介護休業法に基づく育児休業、出生時育児休業、介護休業、子の看護休暇、介護休暇、育児・介護のための所定外労働、時間外労働および深夜業の制限並びに所定労働時間の短縮措置等の適用を受けることができます。また、孫に対しても適用されます。具体的な取扱いについては、「育児・介護休業等に関する規則」で定められていますので、詳細はそちらをご覧ください。
もう一丁、投げてみました。
- 【質問】現在、係長です。課長に昇進したら手当は増えますか?
- 【回答】はい、課長に昇進すると手当が増えます。当社の規定によると、課長の月額手当は200,000ペソです。ただし、昇格による場合は発令日の属する賃金月から支給されます。また、昇給については、勤務成績や業績に応じて行われるため、昇進後の成績によっては手当が増える可能性があります。退職金についても、勤続年数に応じて支給率が定められていますので、長期間勤務することで退職金も増えることになります。
おぉ、200,000ペソですって・・うぅ、感動です。なんとか動作してくれました。
おわりに
OpenAIのようなLLM(大規模言語モデル:Large Language Models、LLM)に独自データ情報を追加して問い合わせる方法は、日々、新しい方法が出てきています。
今回は、Microsoft Azure OpenAI Serviceが提供してくれている基本的な機能だけで頑張ってみました。
最近、Azure OpenAIサービスに、「Add your data機能」がプレビューで利用可能になりました。
この機能は、テキスト以外にも画像に含まれる情報も含めて、独自データ情報を組み合わせてのお問い合わせが可能になっています。(前述のAzure Cognitive Searchが内部で利用されています。)
ただし、2023年7月時点では日本語に完全対応していません。対応を期待しています。
今回は、“就業規則”に関するお問い合わせとしましたが、僕の担当しているコンタクトセンターソリューションである「enjoy.CRMⅢ」にも早い段階で機能追加できるように頑張っていきたいと思います。
- ※Microsoft、Azure、Dynamics 365、Power Platform、PowerPoint、その他のマイクロソフト製品およびサービスは、米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
- ※enjoy.CRMは、株式会社OKIソフトウェアの日本における登録商標です。
- ※ホッピーは、ホッピービバレッジ株式会社の日本における登録商標です。
- ※その他本ページに表示または記載されている各社の会社名・ロゴ・サービス名・商品名等はすべて各社の商標または登録商標です。


